-
Solutions to Overcome the Frame Dropping in Detection Networks
The problem of detection consistency in video object detection is a key challenge. The existing video-based object detection methods extensively apply large networks to every frame in the video to localize and classify targets, which suffers from a high computational cost and hardly meet the low-latency requirement in realistic applications. Despite of substantial work in this space, accuracy of classifiers on adjacent video frames remains much lower than that on normal inputs. Generally speaking, finding out why video frames are dropping will help us come up with a new solution.
Our work is to analyze the similarities and differences between several adjacent frames of images and feature maps under different scenes, models, convolution depths, global and local conditions and to explore a more adequate method of inter-frame analysis and try to find out what caused the frame drop.

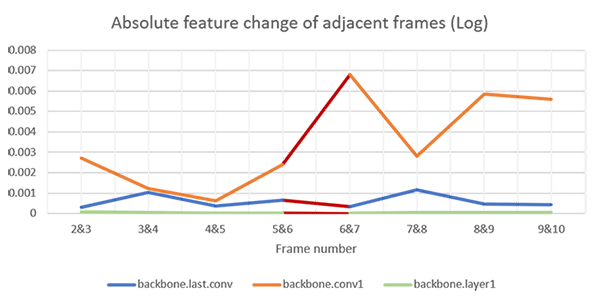
Key findings:
- In the experiments, we found that the generation of the frame drop phenomenon does not mainly originate from the backbone, the existence of the anchor and the detection head process.
- The greater impact depends on the final fc layer i.e. the classifier.
-
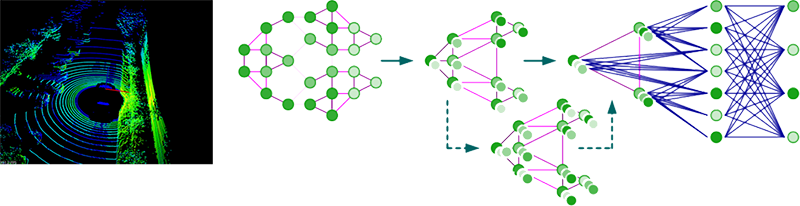
GCN Based Point-Cloud Data Analysis
Point cloud is an important field in computer vision and many applications (e.g. 3D-object detection) are related to it. In recent years, graph convolutional network (GCN) has been designed for dealing with graph structure data and it is powerful on some tasks besides point cloud. We focus on designing GCN learning algorithm to deal with the point cloud tasks (e.g. classification and segmentation) and training an efficient and compact GCN model with high accuracy especially for self-driving.

-
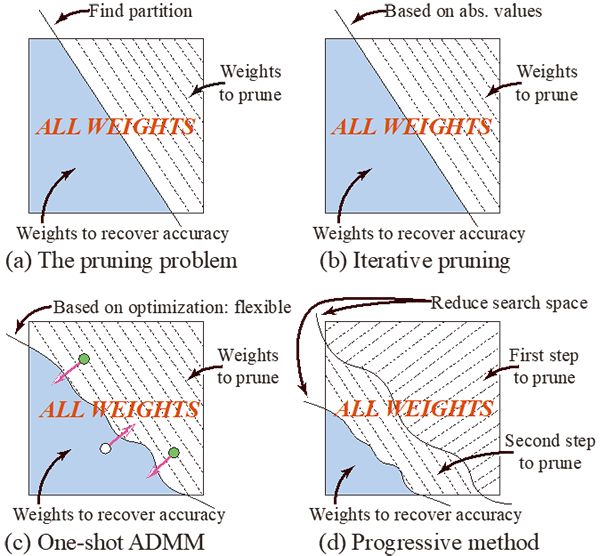
Model Compression: an ADMM Approach for Pruning
Model compression can be seen as a partition problem. The goal is to divide weights into two subsets: One subset for compressing and the other for recovering the accuracy loss due to the compression. In this sense, weight pruning and weight quantization can both be treated similarly. Previous model compression methods have difficulty achieving an extremely high compression rate without a performance degradation. This is mainly because that some weights are essential for keeping neural networks’ performance and compressing them without a right partition procedure can be very harmful. In contrast, our approach progressively apply model compression and use the previously pruned model as a weight initialization for the next step. In every single step, we leverage Alternative Direction Methods of Multipliers and treat model compression as solution for optimization problem. Our progressive ADMM method achieves state of the art model compression rate in multiple benchmarks and still keeps the record.
-
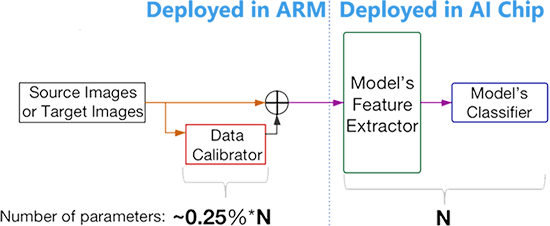
Adapting to New Environment Without Changing the Model in AI Accelerator
Modern neural networks are considered too big for edge devices such as AI chips, so the models are often compressed before deployment. However, when the autonomous cars drive to a new environment, due to lack of robustness, neural networks tend to have performance degradation. Also, because they are compressed, their weights are not able to update. To counter this problem, we propose a light-weight calibrator to act as a pre-processing unit for the main model. The calibrator is so small that it is less than 0.25% of the main model and can be directly deployed in ARM. When it comes to real world task such as driving scene semantic segmentation, it is common that model trained in source domain GTA5 (s-a in the figure) has a huge performance degradation at the target domain CityScapes (t-b in the figure). Our method is capable of maintaining source domain performance (s-c in the figure) while greatly preventing performance degradation in target domain (t-c in the figure).

-
PCONV: Compiler Level Optimization to Achieve Real-Time on Phones
There are currently two mainstreams of pruning methods representing two extremes of pruning regularity: non-structured, fine-grained pruning can achieve high sparsity and accuracy, but is not hardware friendly; structured, coarse-grained pruning exploits hardware-efficient structures in pruning, but suffers from accuracy drop when the pruning rate is high. In this paper, we introduce the PCONV, comprising a new sparsity dimension: fine-grained pruning patterns inside the coarse-grained structures. PCONV comprises two types of sparsity, Sparse Convolution Patterns (SCP) which is generated from intra-convolution kernel pruning and connectivity sparsity generated from inter-convolution kernel pruning. Essentially, SCP enhances accuracy due to its special vision properties and connectivity sparsity increases pruning rate while maintaining balanced workload on filter computation. To deploy PCONV, we develop a novel compiler-assisted DNN inference framework and execute PCONV models in real-time without an accuracy compromise, which cannot be achieved in prior work. Our experimental results show that PCONV outperforms three state-of-art and end-to-end DNN frameworks, TensorFlow-Lite, TVM and Alibaba Mobile Neural Network with speedup up to 39.2×, 11.4× and 6.3×, respectively, with no accuracy loss. Mobile devices can achieve real-time inference on large-scale DNNs.
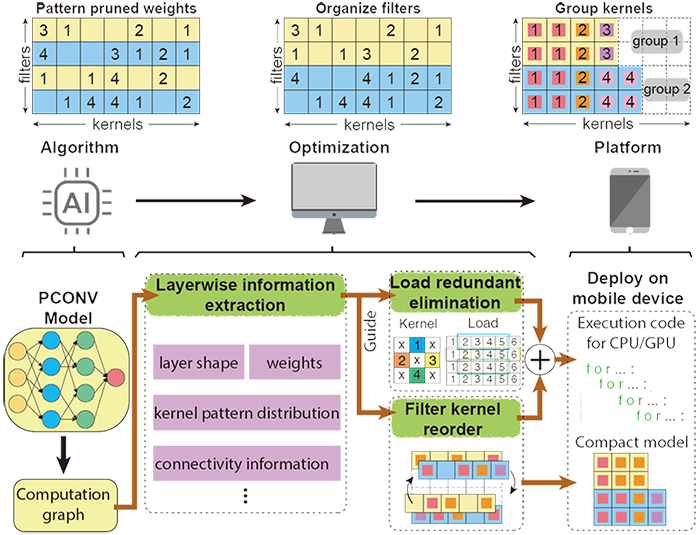
-
MUSE Architecture: Accelerate while Maintaining the Accuracy through Pattern Pruning
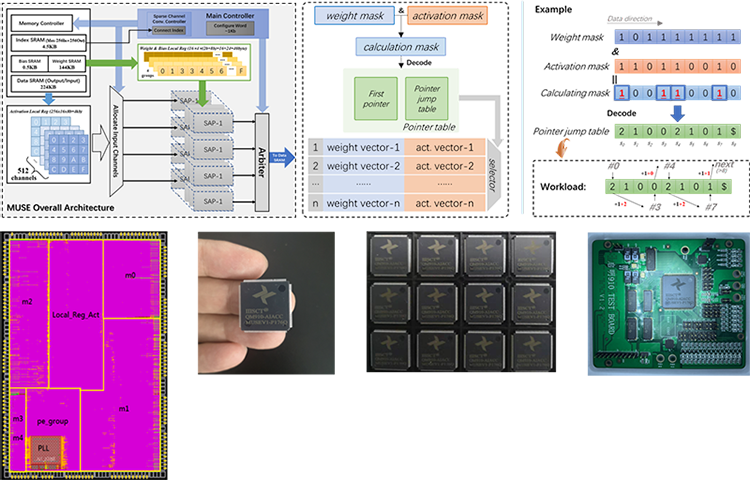
We propose the PCNN, a fine-grained regular 1D pruning method. A novel index format called Sparsity Pattern Mask (SPM) is presented to encode the sparsity in PCNN. Leveraging SPM with limited pruning patterns and non-zero sequences with equal length, PCNN can be efficiently employed in hardware. Evaluated on VGG-16 and ResNet-18, our PCNN achieves compression rate up to 8.4× with only 0.2% accuracy loss. We also implement a pattern-aware architecture in 55nm process, which can employ the proposed pattern pruning into our hardware. It achieves up to 9.0× speedup and 28.39 TOPS/W efficiency with only 3.1% on-chip memory overhead of indices.
We also point out that the actual performance is mainly decided by PE utilization and off-chip bandwidth requirements. For PE utilization, we discover that kernel-level pruning ,one kind of structured pruning, easily leads to under-utilization of PEs. By proposing a novel reordered-based scheduling method, we achieve more than 15% utilization improvement in 70% sparsity case. For off-chip bandwidth requirements, we develop a sparsity-aware dataflow to optimize various layers with different percentage of zeros with improved off-chip bandwidth requirements;
Furthermore, we develop a dynamic quantization ALU to support three kinds of weight quantization methods including fix-point, power of 2 and mix power of 2 in different scenarios.
-
AI Chipset QIMING-910 Design
QIMING-910 is our first tape-out for sparsity-aware acceleration. The architecture of the chip leverages ternary-quantization (-1, 1, 0) for weights, with which we can just design MUX-based ALUs for multiplication instead of complicated logics to implement multipliers. Moreover, using ternary-quantization significantly saves memory overhead by 16X compared to the single floating-point number. Based on ternary-quantization, the percentage of zeros is increased dramatically and thus it provides an opportunity for us to skip redundant multiplication when the weight is zero. Therefore, we correspondingly propose a zero-aware processing element to selectively process data in a vector issued from the buffer.
Fabricated in the UMC 55nm SP CMOS process, QIMING-910 achieves peak performance and power efficiency of 204.8 GOPS and 3.16 TOPS/W respectively. It can run under voltage of 0.8-1.2V from 10MHz to 300MHz. With the power of ternary-quantization, multiplier-free ALU design and zero-aware processing, the power efficiency is 2X ~ 10X compared to state-of-the-art. We design a testing board connected to Xilinx Virtex-7 FPGA VC707 via FMC. VC707 here serves as a controller rather than a processor to transfer data from PC to our chip. The overall system can accomplish image classification task enabled by VGG-16 on CIFAR-10 dataset. Currently, we are about to complete the development of the next generation chip that supports more neural network models with high-efficiency configurable dataflow. We will also put a pattern-aware architecture into the next generation chip.
-
System Level Solution for Self-Driving
With the deepening of the scientific and technological revolution, autonomous driving technology has gradually become the focus of the industry with the rapid development of artificial intelligence and automobile industry. Due to the limited computational power of traditional solutions based on GPU, CPU or FPGA, it is difficult to achieve the purpose of the application on cars. In this context, our team developed a new AI chip named QIMING-910 for target classification and detection, which has been successfully taped out. With this chip, we plan to design a fully developed autonomous driving solution. Our scheme consists of three main parts, the first front-end sensor data acquisition, then the AI chip to accelerate calculation of the data and the classification results back to the car master control unit and auxiliary car on autopilot.
The rapid development of self-driving technology has the ability to reshape automotive business and transportation, distribution, logistics industry chain and relevant market. We are on board!

