Currently, the brain-computer interface (BCI) has enabled people to control wheelchairs and prostheses, yet the potential of controlling ability is limited by the relatively slow speed of signal processing, which takes seconds to process imaginary movements. In addition to that, the development of artificial intelligence demands further understanding of the mechanism of brain. It’s now clear that the current generation of AI has met its bottlenecks as it is difficult to do small sample learning and lacks robustness to defend adversarial attacks and ability to do reasoning. Therefore, in this project, we developed a framework to push the development of both BCI and the next generation of AI that is more brain-like. By constructing a digital copy of brain, we are able to evaluate the model’s ability of learning and impacting the brain. The joint study of BCI and artificial intelligence calls for new design ideas.
We use emotional images and sounds as inputs and use functional near - infrared spectroscopy (fNIRS) to collect activities across brain.
Key findings:
- Depressed patients have a longer elimination time of negative emotions, while normal people have approximately the same elimination time of positive and negative emotions.
- In all superficial brain regions, the emotion-related regions are mainly distributed in the prefrontal lobe. We synthesized the music using the information collected from the 48 brain regions and found that the music was very messy. The music composed of 6 strongly correlated brain regions in the prefrontal part is more pleasant.
Visualizing brain activity using synthesized music,48 channels
Using only 6 strongly correlated regions in the prefrontal part
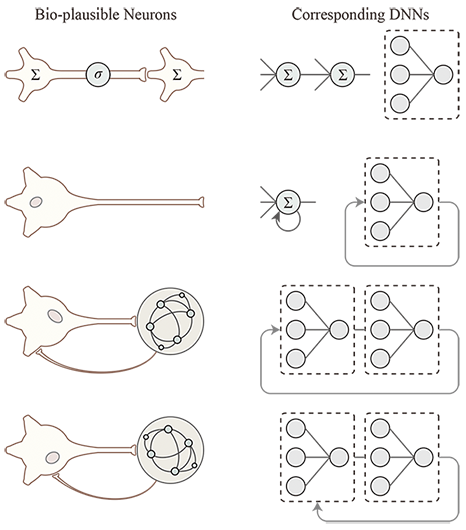
Brain-spired Algorithms to Mimic Feedback Circuits in the Brain
Deep Neural Networks (DNNs) are criticized for the weak robustness to natural corruptions, domain-shifts and adversarial attacks, while mammal brains are claimed to be far more robust than DNNs. For a long time, a more expressive and bio-plausible architecture, Spiking Neural Network (SNN), is widely adopted for design brain-mimic models and is believed to be the next (3rd) generation of neural networks. However, the non-differential and non-structural nature of spiking codes makes SNNs lack effective learning theories, especially when gradient descent, the critical reason of DNN being a success, is not applicable. The huge expression gap between neurons of DNNs and SNNs does exist and should be bridged by some 2.5th generation neural networks, which can take advantages from the bio-plausible features of SNNs and benefit from the developed theories and platforms of DNNs at the same time.
Recurrence in time and feedback in connections are two characteristics of neural systems, and the latter has been proved to be one of the sources of robustness in ventral stream of human vision. Recurrence and feedback can be implemented at different levels from neuron to block connection, which leads to a vast possible space of the 2.5th generation neural networks.
Using Association Mechanism to Achieve Model Robustness
Human associate new knowledge with old ones from their past experience. This particular mechanism is potentially one of the reasons why human brain is more robust to environmental variants. Inspired by the mechanism, we use a similar mechanism when training and deploying neural networks. To improve neural networks’ robustness against various perturbations, we develop a tiny network to modify inputs of neural networks to minimize the classification loss of the main model. When we visualize the modified inputs, we see an increasing attention on objects’ shape instead of textures. We see this as an indicator that the neural networks tend to be more resistant to perturbations and corruptions if they pay more attention on objects’ shape instead of textures. This is directly related to several psychological evidences found in human studies.
Using Auxiliary Training to Increase Model Robustness
The deployment of the network in applications has two strict requirements on both accuracy and robustness. However, most existing approaches are in a dilemma, for example model accuracy and robustness form an embarrassing tradeoff -- the improvement of one leads to the drop of the other. The challenge remains when we try to improve the accuracy and robustness simultaneously. To solve this problem, we propose a novel training method via introducing the auxiliary classifiers for training on corrupted samples, while the clean samples are normally trained with the primary classifier. In the training stage, a novel distillation method named input-aware self distillation is proposed to facilitate the primary classifier to learn the robust information from auxiliary classifiers. Along with it, a new normalization method - selective batch normalization is proposed to prevent the model from the negative influence of corrupted images. At the end of training period, a L2-norm penalty is applied to the weights of primary and auxiliary classifiers such that their weights are asymptotically identical. Extensive experiments on CIFAR10, CIFAR100 and ImageNet show that noticeable improvements on both accuracy and robustness can be observed by the proposed auxiliary training. On average, auxiliary training achieves 2.21% accuracy and 21.64% robustness improvements over traditional training methods on CIFAR100.
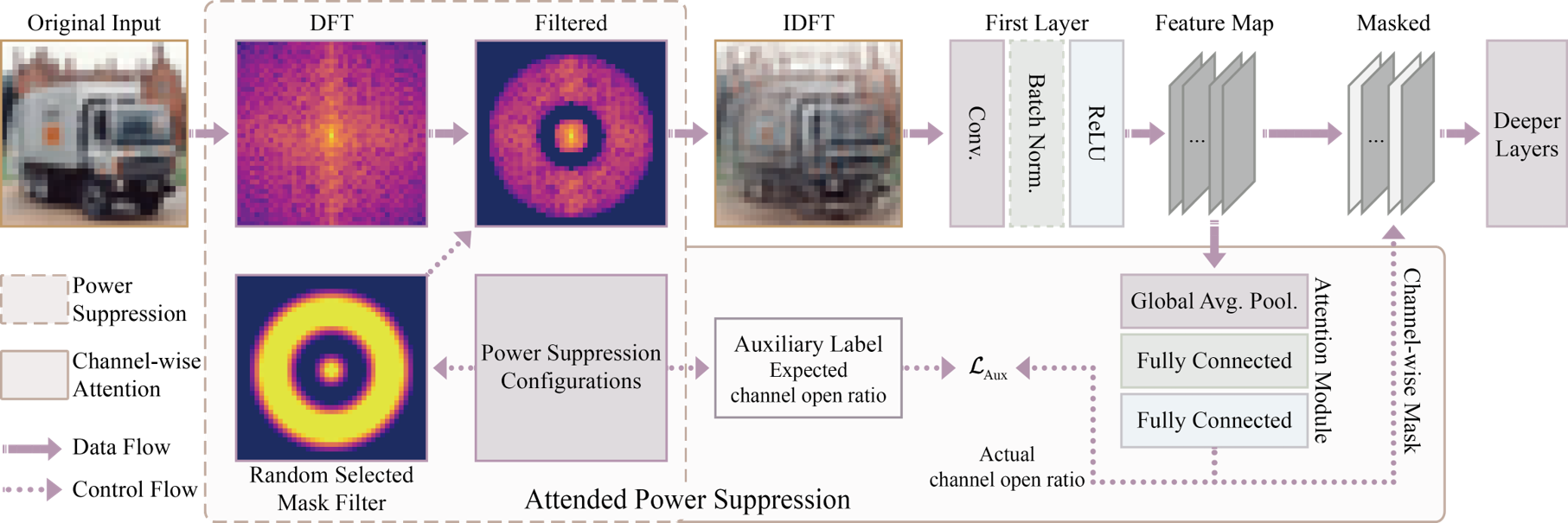
Frequency Interpretation of Neural Networks
Convolutional Neural Networks (CNNs) are known for their high accuracy, low robustness and black-box nature. Adversarial samples and nature corruptions can easily fool a CNN model, while it has been proved that adversarial attacks mainly distribute its energy in high-frequencies, and different corruption types have their own perturbation patterns in frequency domain. The relation between model robustness and frequency-domain interpretation should be revealed. However, many existing interpretation methods of CNNs mainly analyze in spatial domain, yet model interpretability in frequency domain has been rarely studied. To the best of our knowledge, there is no study on the interpretation of modern CNNs from the perspective of the frequency proportion of filters. In this work, we analyze the frequency properties of filters in the first layer as it is the entrance of information and relatively more convenient for analysis. By controlling the proportion of different frequency filters in the training stage, the network classification accuracy and model robustness is evaluated and our results reveal that it has a great impact on the robustness to common corruptions. Moreover, a learnable modulation of frequency proportion with perturbation in power spectrum is proposed from the perspective of frequency domain. Experiments on CIFAR-10-C show 10.97% average robustness gains for ResNet-18 with negligible natural accuracy degradation.
Key findings:
Frequency domain affects only robustness and has little influence on accuracy of clean data.
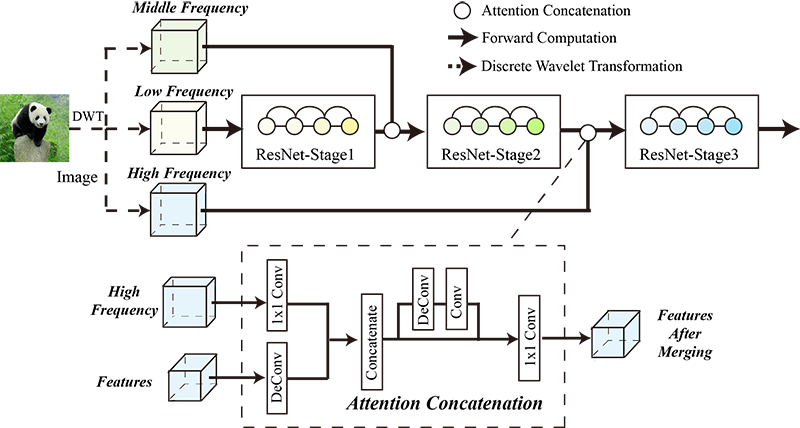
Wavelet-Jnet: A New Model from the Perspective of Frequency
It is well acknowledged in image processing domain that information can be decomposed into different frequency parts and each part has its own merits. However, existing neural networks always ignore the distinctions and straightforwardly feed information into neural networks altogether. We propose a novel neural networks framework named J-Net that decomposes images into different frequency bands and then processes them sequentially. Concretely, the input images have been decomposed by a given wavelet transformation and then the wavelet coefficients are fed into the deep neural networks gradually in different depth according to their decomposition levels. An attention module is utilized to facilitate the fusion of neural network features and inject information, yielding a significant performance gain. Experiments show that 5.91%, 5.32% and 2.00% accuracy improvements on Caltech 101, Caltech 256 and ImageNet datasets, respectively. We further reveal how the information with different frequency impacts the prediction of neural networks and study the influence of frequency injection order and other frequency decomposition methods such as DCT (discrete cosine transform) and DFT (discrete Fourier transform). This work may open up a new opportunity for investigating the frequency information for designing neural network architectures.
Self-Distillation
Convolutional neural networks have been widely deployed in various application scenarios. In order to extend the applications' boundaries to some accuracy-crucial domains, researchers have been investigating approaches to boost accuracy through either deeper or wider network structures, which leads to an exponential increment of computational and storage cost, delaying the responding time.
To solve this problem, we propose a general training framework named self distillation, which notably enhances the performance (accuracy) of convolutional neural networks through shrinking the size of the network rather than aggrandizing it.
Different from traditional knowledge distillation - a knowledge transformation methodology among networks, which forces student neural networks to approximate the softmax layer outputs of pre-trained teacher neural networks, the proposed self distillation framework distills knowledge within network itself. The networks are firstly divided into several sections. Then the knowledge in the deeper portion of the networks is squeezed into the shallow ones.
Experiments further prove the generalization of the proposed self distillation framework: enhancement of accuracy at an average level is 2.65%, varying from 0.61% in ResNeXt as minimum to 4.07% in VGG19 as maximum.
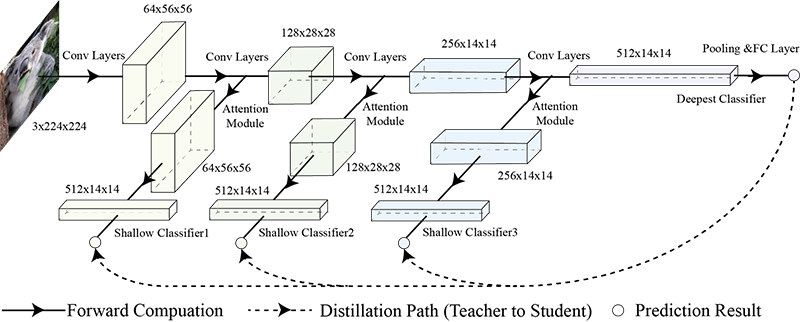
SCAN:A Dynamic Inference Framework
Remarkable achievements have been achieved by deep neural networks in various applications. However, the increasing depth and width of such models also leads to an explosive growth in both storage and computation, which has restricted the deployment of deep neural networks on resource-limited edge devices. To address this problem, we propose the so-called SCAN framework for networks training and inference, which is orthogonal and complementary to the existing acceleration and compression methods. The proposed SCAN firstly divides neural networks into multiple sections based on their depths and constructs shallow classifiers upon the intermediate features of different sections. Moreover, attention modules and self distillation are utilized to enhance the accuracy of shallow classifiers. Based on this architecture, we further propose a threshold controlled scalable inference mechanism to approach human-like sample-specific inference, which leads to an extra acceleration. Experimental results show that SCAN can be easily equipped on various neural networks without any adjustment on hyper-parameters or neural networks architectures, yielding significant performance gain on CIFAR100 and ImageNet. We also find that the proposed SCAN can be utilized to improve the performance of other model compression methods, such as knowledge distillation, pruning and lightweight models design.
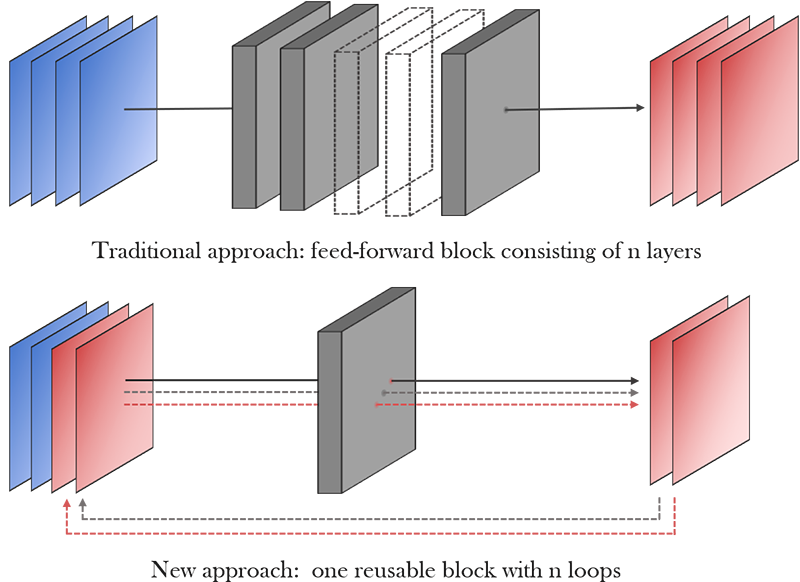
LoopNET:A Novel Approach to Overcome Memory Wall Problem
Deep Convolutional Neural Networks have by now established themselves as powerful tools to tackle some of the most complex tasks in Computer Vision such as image recognition, object detection and segmentation. Although they carry immense potential, they are very much constrained in their edge deployment because of their computational complexity, parameter burden and high inference time.
Previously, strategies such as pruning and knowledge distillation (KD) have been proposed to turn very successful deep models into more shallow ones. These shallower models, however, can suffer from severe performance degradation because of lacking depth (even after KD) or be difficult to deploy on hardware.
We propose an architecture that replaces deeper layers by recurrent connections to reduce parameter count and limit inference time. These loops allow us to limit parameter count and due to the fact that retrieving a Convolutional Layer from memory is a more time-consuming task than performing the actual convolution operation we can actually go deeper for the same inference time.
These looped architectures come with challenges of their own, especially when trying to guarantee stable training. Therefore, we develop training methods and architecture modifications such as re-injecting inputs for convergence.